| # | Problem | Pass Rate (passed user / total user) |
|---|---|---|
| 12186 | Word Puzzle Patterns |
|
| 12226 | Bus Route Distance Linked List |
|
| 12246 | Tic-Tac-Toe Tree Path |
|
| 12291 | Video Streaming Network Quiz |
|
| 12313 | Secret Codes Quiz |
|
Description
What:
The Data Structures TAs enjoy making word puzzles. Ron has challenged Eva to find all combinations of letters matching the following rule:
c(v)+(c(v)+)+c
Where c is a consonant and v is a vowel. This means: all strings of concatenations of at least two groups of one consonant followed by one or more vowels, followed by a consonant at the end (ex.: papap, paaaapaaaaap, papapap). Notice that the minimum length for this pattern is length=5.
Eva wants to check her answers. Help them build that program!
How:
You will be given 2 things: the word puzzle dimension and the word puzzle. You should traverse the matrix from left to right, from top to bottom. For each cell, output all possible paths matching the pattern in the traversal order. To change direction, use the following priorities: down, right, up, left.
You should also output the rearranged version of the word, where vowels go first and consonants after (example: apple turns into aeppl).
Example:
For example, take the word puzzle below:

Let’s take a look at some combinations:
XS is not valid, because you have 2 consonants in a row
AD is not valid, because it begins with a vowel
CAT is not valid, because there should be a vowel and a consonant to match the pattern
COZDP is not valid, because there are three consonants together
COZOB is valid, because it is of length>=5 and matches the pattern
XUVAIC is valid, because it is of length>=5 and matches the pattern
NIAVUX is valid, because it is of length>=5 and matches the pattern
HINT: use queue/stack to solve this problem.
Input
1 line: What: an integer n and a new line character
Why: matrix dimension will be (n*n)
n lines: What: n lines of n characters followed by a new line character
Why: word puzzle layout
(n+1 lines in total)
Output
You should all ‘words’ matching this pattern, followed by a space, the rearranged version of the words(vowels before consonants) and a newline character. Output should match the traversal order:
1)down
2)right
3)up
4)left
Sample Input Download
Sample Output Download
Tags
Discuss
Description
Given a series of bus route insertions, build a bus route. Given a series of distance queries, calculate the number of stops in between the source and destination (not the number of unique nodes in the linked lists, you will have to consider 2 directions to calculate distance).
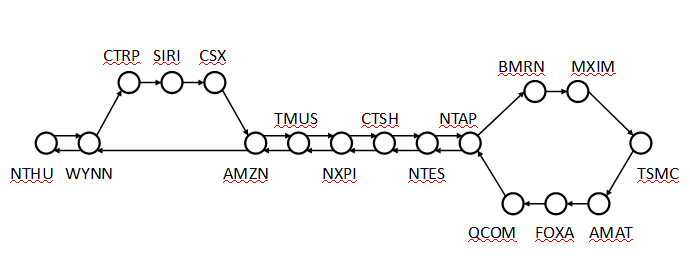
The bus route contains NTHU and TSMC in the beginning.
The operations you must implement are listed below:
INSERT (src, dst, new, method)
src: the name of the source bus stop
dst: the name of the destination bus stop, which is next to the src stop
new: the name of the newly added bus stop
method:
1: insert the new stop in between srcdst
2: In addition to srcdst, also insert the same stop in between dstsrc if appropriate
RENAME (old_name, new_name)
Replace the stop with the old_name with the new_name
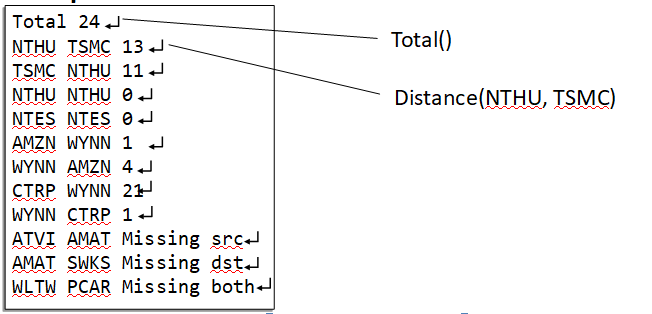
TOTAL ()
Output the total number of stops starting from NTHU and back to NTHU (NTHU is only counted once)
DISTANCE (src, dst)
Output the minimum number of stops from src to dst
If src or dst does not exist, output “Missing src”, “Missing dst”, or “Missing both”
No deletion or reversion operations.
Example route from input:
Input
- An integer n, representing number of operations, followed by newline
- N lines, representing the operations. Each line will look like below:
- 'RENAME', 'old name', 'new name', separated by a whitespace, with new line at the end, OR
- 'INSERT', 'source name', 'destination name', 'new station to insert' separated by a whitespace, with new line at the end
- An integer m, represeting the number of distances you should output, followed by newline
- M lines, the distances to calculate. Each line will look:
- 'source name' and 'destination name', separated by a whitespace, with new line at the end

Output
- The word 'total', followed by the number of stops in the bus route (traversing starting from NTHU and ending back in NTHU, not the number of unique nodes in the linked lists you will have to consider 2 directions to calculate distance), separated by whitespace and followed by a new line
- m lines representing the distances, each line will look like below:
- If both stations exist: 'source name', 'destination name', number of stops in between, separated by whitespace and followed by a new line
- If source station src doesn't exist: 'source name', 'destination name', and 'Missing src', separated by whitespace and followed by a new line
- If destination doesn't exist: 'source name', 'destination name', and 'Missing dst', separated by whitespace and followed by a new line
- If neither destination nor source exist: 'source name', 'destination name', and 'Missing both', separated by whitespace and followed by a new line
Sample Input Download
Sample Output Download
Tags
Discuss
Description
Given:
- A series of nodes representing the possible steps in Tic tac toe
- A tic-tac-toe grid
Task:
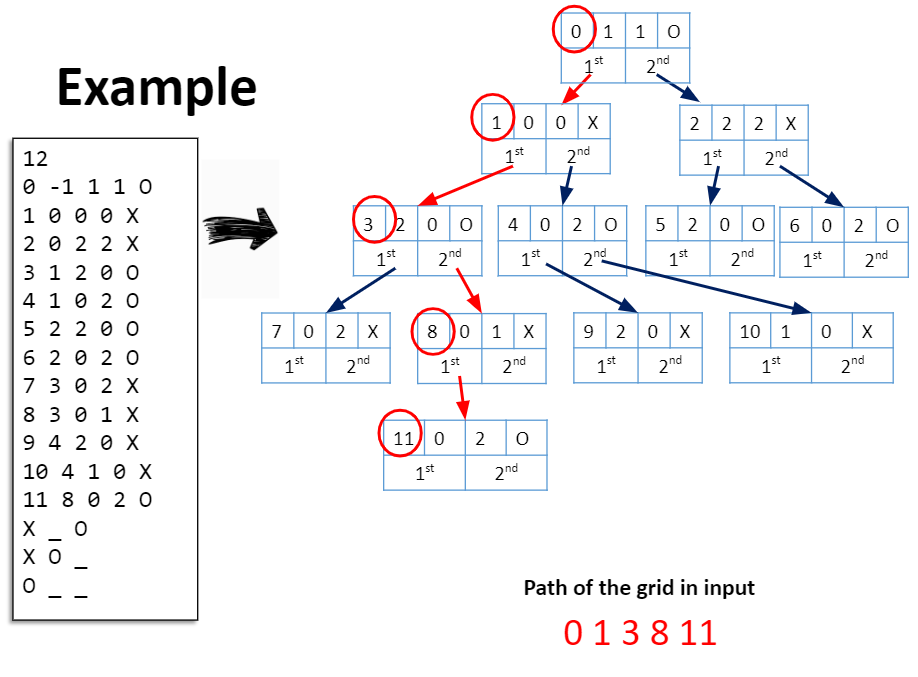
- Convert the input data into a tree
- Find the root to node path leading to the grid (starting from root)
Input
- An integer N, the number of nodes in tree , newline at the end
- N lines indicating the node contents. Each line looks like below:
Node Id, Parent Id, Position x, position Y, Mark (either 'O' or 'X'); separated by whitespaces, newline at the end - 3 lines, with the Tic-tac-toe grid:
- Each line has 3 marks (‘X’,’O’,’_’), separated by whitespaces, newline at the end
Notes:
- Node Id is an integer ranging from 0 to 100.
- Parent Id is an integer ranging from-1 to 99, where -1 is the root.
- Position x and position y are integers ranging from 0 to 2, indicating the tic-tac-toe grid position.
- The tic-tac-toe gris positions are illustrated below:

Output
IDs of the nodes in the path leading to the grid, separated by whitespaces, followed by a new line. (Starting from root)
Sample Input Download
Sample Output Download
Tags
Discuss
Description
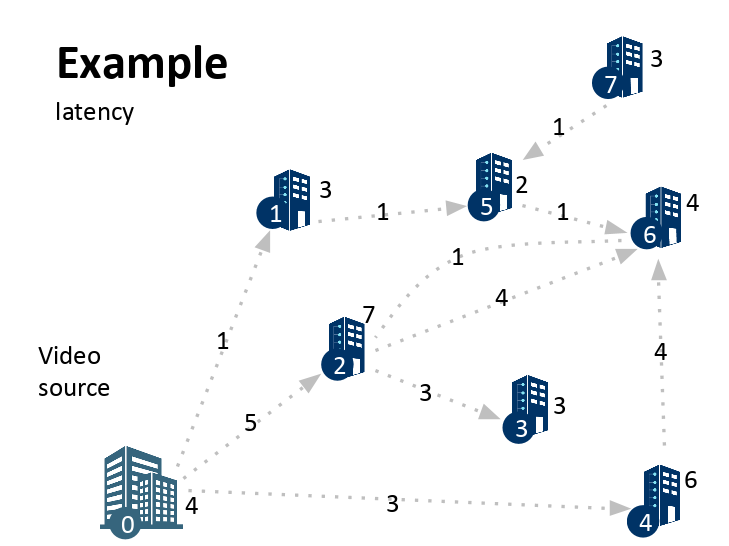
The Data Structure TAs are trying to set a video streaming service in campus. There are several buildings in the campus, we want to stream to all of them from building '0'. We want to find the"optimal" way to stream to each destination from our source building '0'. Luckily, solving this problem is equivalent to building a Minimum Spanning Tree!
You will be given M connections for N buildings. Each building is specified by its latency (ie. this time, not only edges have latency, but buildings too). Each connection is specified by: source building, destination building, latency and bandwith. You should first build a graph with the buildings as nodes, and connections as edges. You should then build the minimum spanning tree. Finally, you should find the Min-Latency for each building, that is the minimum latency sum (ie.sum of the latencies from all edges in the path) from all paths from destination to source (including both source and destination stations).
An example of the Graph and Minimum Latency is given below:
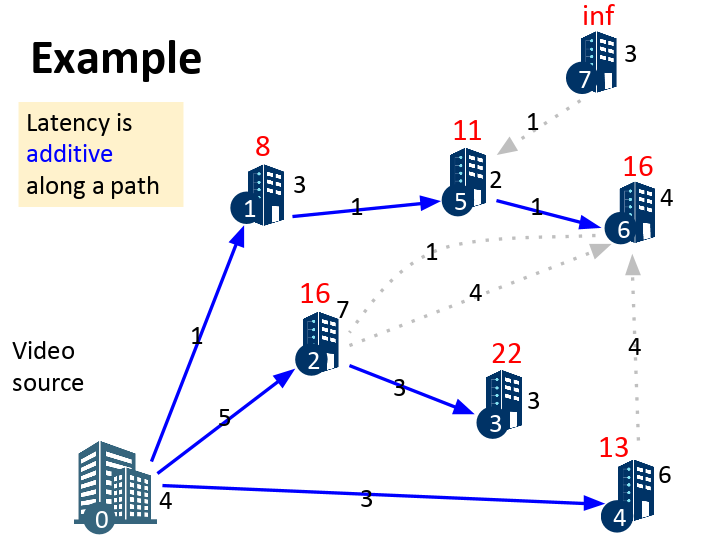
Input
- An integer n, the number of buildings (n<1000)
- N lines with the latencies of buildings 0 - N-1
- An integer m, the number of candidate connections
- M lines with the candidate connections, each line will have 3 integers, which represent:
- source building number, destination building number, Min Latency; separated with withespaces, with newlines at the end, where: 0<Latency<11
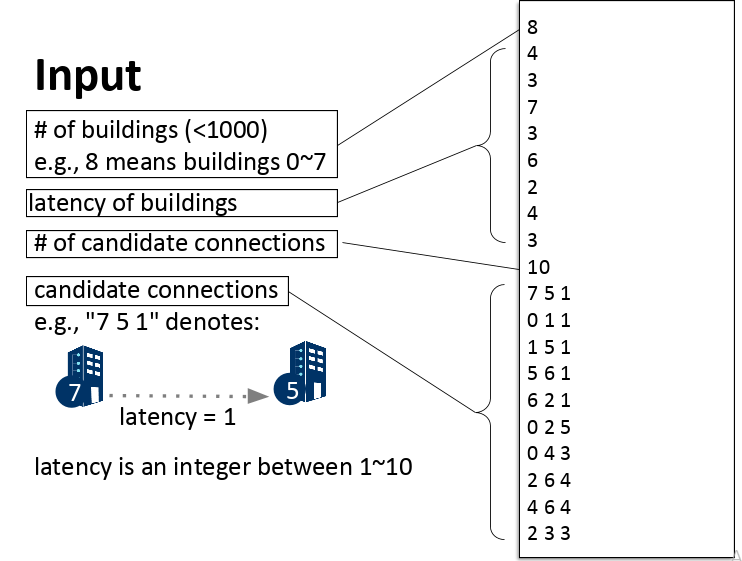
Output
- N-1 lines, one for each building except for the source, building '0', with 2 integers:
- Building no. and Min Latency; separated witht whitespaces, with newline at the end.
- Note:
- For an unconnected building, Min latency will be the 3 character string "inf".
Sample Input Download
Sample Output Download
Tags
Discuss
Description
You will be given a text and a word. You should:
- Calculate the character distribution in the text and sort it using stable ascending sort (from low to high).
- Reorder the word using the character distribution order.
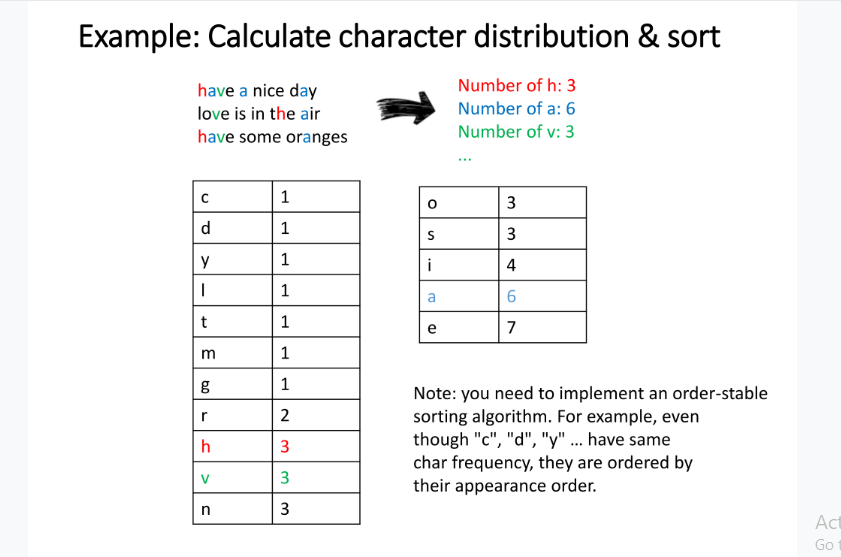
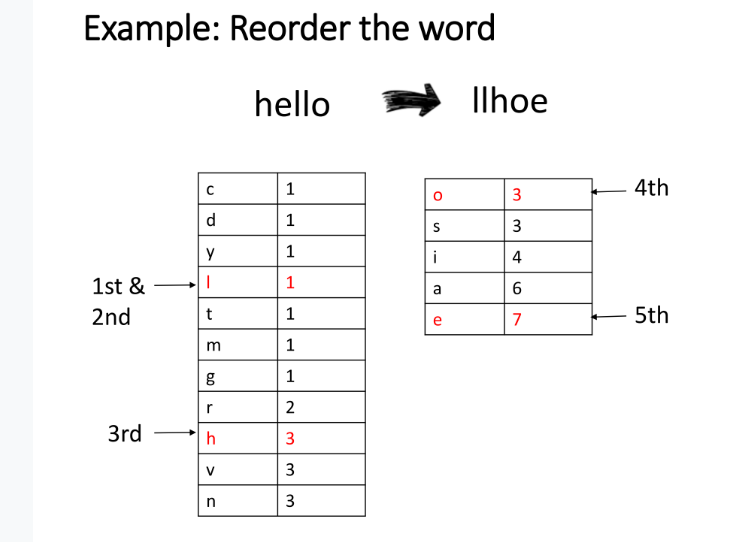
Input
- The first line of input contains a single positive integer n (number of lines of the text) and a word, separated by a comma, followed by newline
- The next n lines contains zero or more characters(with whitespace), they all end in newlines. This will be the text.
Output
The reordered word using the character distribution order, followed by a new line