Description
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web.
Generally, a Web crawler visits a website, reads the HTML code of the website, gathers information it wants, and probably wants to visit the links it found in this website.
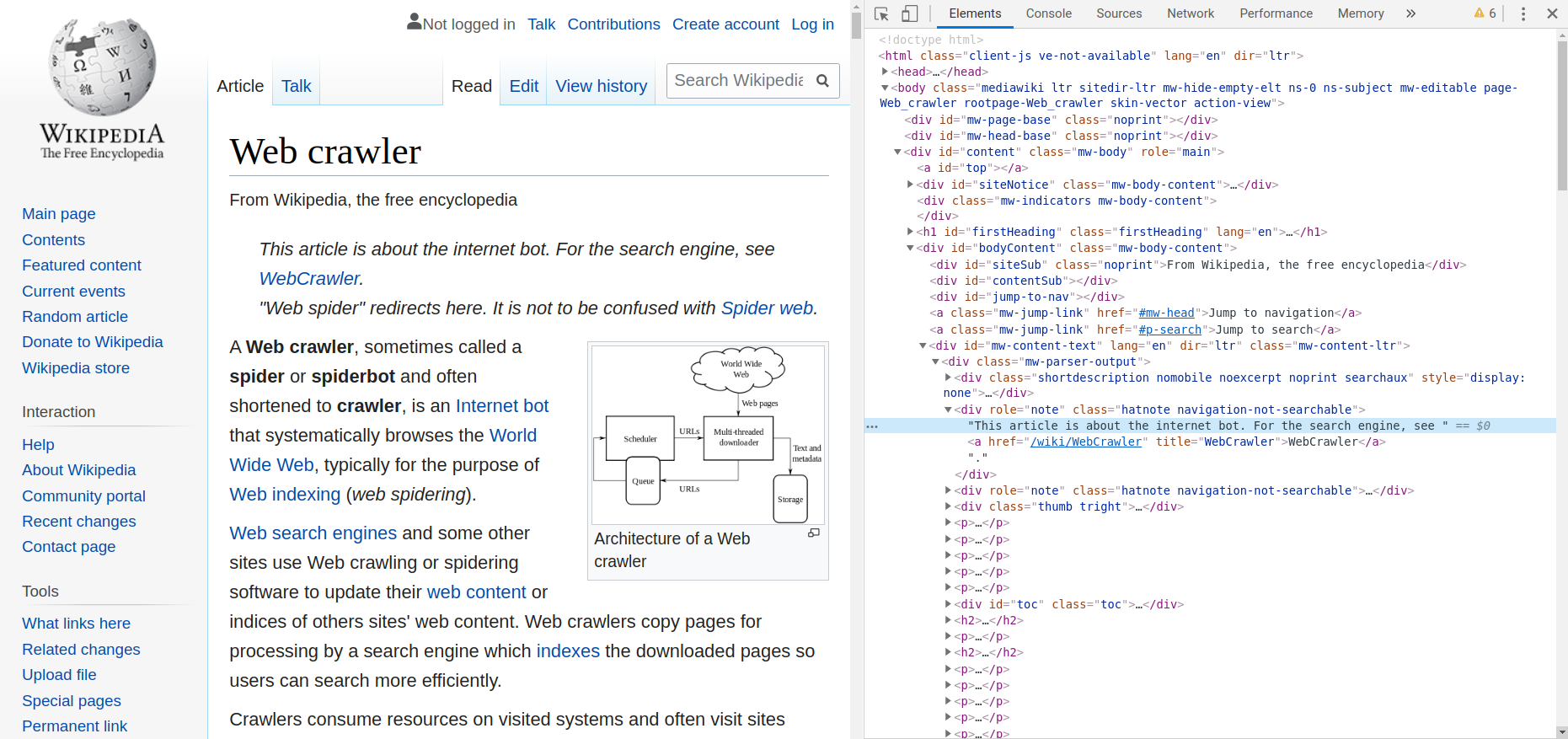
For example, if a Web Crawler visits the wikipedia webpage introducing "Web crawer" (the webpage is shown in the left part of the image) ...
-
It reads the html code of the webpage (shown in the right part of the image)
-
It gathers information. For example,
-
It finds the definition of "Web Crawler"
-
It finds several links (i.e. the blue words in the webpage), such as links to "Internet bot", "World Wide Web", etc.
-
-
It probably wants to visit the links "Internet bot", "World Wide Web", ... one by one to get more information.
In this problem, you are going to implement a simple Web crawler. Given the html code of some website, you are going to output several information :
-
Title of the website
The title of the website is the string placed within <title> and </title>, for example, the title in sample input is "This is the title".
-
Numbers of links in this webpage
A link in html is in the following syntax : <a href="url">link text</a>, where url is the link address and link text is the text of the link.
Refer to the to Sample IO for output format.
Hints
-
What is html code?
-
In this problem, you only need to know that html code are several lines of strings in some special format.
-
html code are tags in the following format :
<tagname>contents of tag</tagname> -
In Chrome, you can press
F12key to see the html code of the website
-
-
How to read in html codes?
-
Some useful functions you've learned in previous homework 12507 - Searching Remark :
-
char *strtok(char *str, const char *delim)- to break stringstrinto a series of tokens using the delimiterdelim, which is defined understring.h -
char *fgets(char *str, int n, FILE *stream)- to read a string of lengthninto stringstrfrom a file streamstream(e.g.stdin), which is defined understdio.h
-
-
How to find title?
-
Why not start with finding the position of
<title>and</title>? The substring between<title>and</title>is the title of the website.
-
-
How to count links?
-
For every link in html, it must contains the substring
</a>. This problem can be solved by counting the number of occurrence of</a>.
-
Input
You will be given a HTML code. Input contains at most 100 lines. Each line contains at most 1000 characters.
Technical Restrictions
Only the following tags will appear in the input :
-
<html> </html> -
<head> </head> -
<body> </body> -
<title> </title> -
<a> </a> -
<h1> </h1> -
<p> </p>
All tags except for <head></head> and <body></body> will be on the same line.
In each case, there will be exactly one <head></head>, one <body></body>, one <title></title>.
It is guaranteed that the contents of tags will not contain '<' or '>'.
Output
For the first line, please output the title of the given website.
For the second line, please output the number of links in the given website.
Remember to add new line character in the end of each line.