Description
Data discretization, one technic of data preprocessing, is to transform the data from complicated data into computable data, which is the critical part in a lot of application, such as Machine Learning.
In this problem, you’re asked to discretize sevaral data (name, label) (xi,yi) according to the given transform table T.
The table T consists of 2 part, before and after, which means the label y should be afteri if y is as same as beforei. Otherwise, y will become unlabeled.
After processing all data, you also have to accumulate the number of data with label = beforei for each beforei, and outputs them in the same order with table T.
For example:
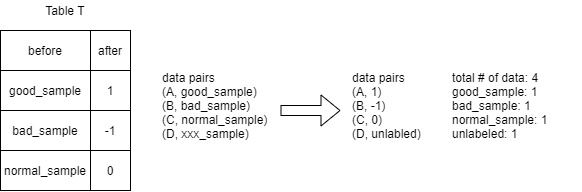
Steps:
Because the brute force method may get TLE on some testcases, TA recommonds to use 3 std::map
std::map<string, int> BA: stores (beforei, afteri) pair, in lexicological order of beforestd::map<string, int> Count: stores (beforei, Ki) denoting there’re Ki data have label = beforeistd::map<int, string> Index: store (i, beforei), which means beforei is the ith element in table T
Step 1: Read (beforei, afteri) pair, and initialize BA, Index.
Step 2: Read data (name, label), transform label by BA, and output the result.
Step 3: Accumulate the number of data with label = beforei by Count.
Step 4: Output (beforei, Ki) pair with the input order, which can be obtained by Index.
How to use std::string
#include <string>
#include <iostream>
using namespace std;
int main(){
string s;
while( cin >> s ){ // input a string until EOF
cout << "My string: " << s << endl; // string output
if( s == "XXX" ){ // built-in string comparator
cout << "s is \"XXX\"" << endl;
}
};
return 0;
}
Input
There’re multiple lines of input.
The input can be separate into 2 parts by “----------” ( ten '-' ).
The first part represents the transform table T.
Each line consists of (beforei, afteri) in table T, where beforei is a string, afteri is an integer.
The second part represents the data set.
One data (xi, yi) for one line, where xi, yi are strings.
It’s guaranteed that:
- 1 ≤ |beforei|, |xi|, |yi| ≤ 500
- beforei, xi, yi consist of lowercase alphabets.
- −10000 ≤ afteri ≤ 10000
- beforei ≠ beforej, afteri ≠ afterj for all i ≠ j
- The total number of data pairs ≤ 50000
- The size of table T ≤ 10000
Please refer to Sample Input for the precision format.
Output
First, print each data pair after discretization for one line.
Second, output the total number of data pairs.
Third, print several lines of beforei: Ki, where Ki the number of data pairs with label beforei.
Last, print the number of unlabeled data.
Notice that, the order of beforei: Ki in third part should be as same as input order.
Please refer to Sample Output for the precision format.