Description
In this problem, we will learn how to encode the text and decode the encoded message.
If there are some character have the same frequency, please order them according to the order of occurrence.
Input
There are two lines of text, the first line is the text which learns the encoding rule, and the second line is the message for you to decode.
You can follow the example rule:
Example Input:
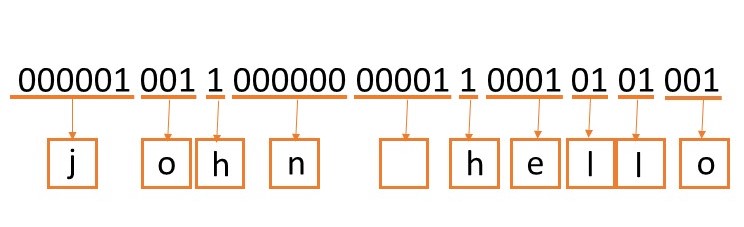
Hello john
000001001100000000001100010101001
Note that
1. You can use the built-in function .lower() to convert the character to lower-case.
2. Not all elements are characters. Hint: Please also take 'space' in counting.
Output
After counting and sorting,
You will get
'h' for 2 times
'i' for 2 times
'o' for 2 times
'e' for 1 time
...
Encode:
The order of the characters will encode follow the rule as following, we will encode the first most frequent character to '1'.
Encode the second most frequent character to '01'. (plus a '0' in front of the next character)For example,
'h' is the most frequent character, we encode it to '1'.
'l' is the most frequent character, so we encode it to '01'.
'o' is the most frequent character, so we encode it to '001'.
'e' is the second frequent character, so we encode it to '0001'.
' ' is the second frequent character, so we encode it to '00001'.
'j' is the second frequent character, so we encode it to '000001'.
'n' is the least frequent character, so we encode it to '000000'Followed by this rule, we can encode all our characters.
Decode:
You need to decode the second line of the input text, which is 000001001100000000001100010101001 in the sample test case.
Example Output:
john hello